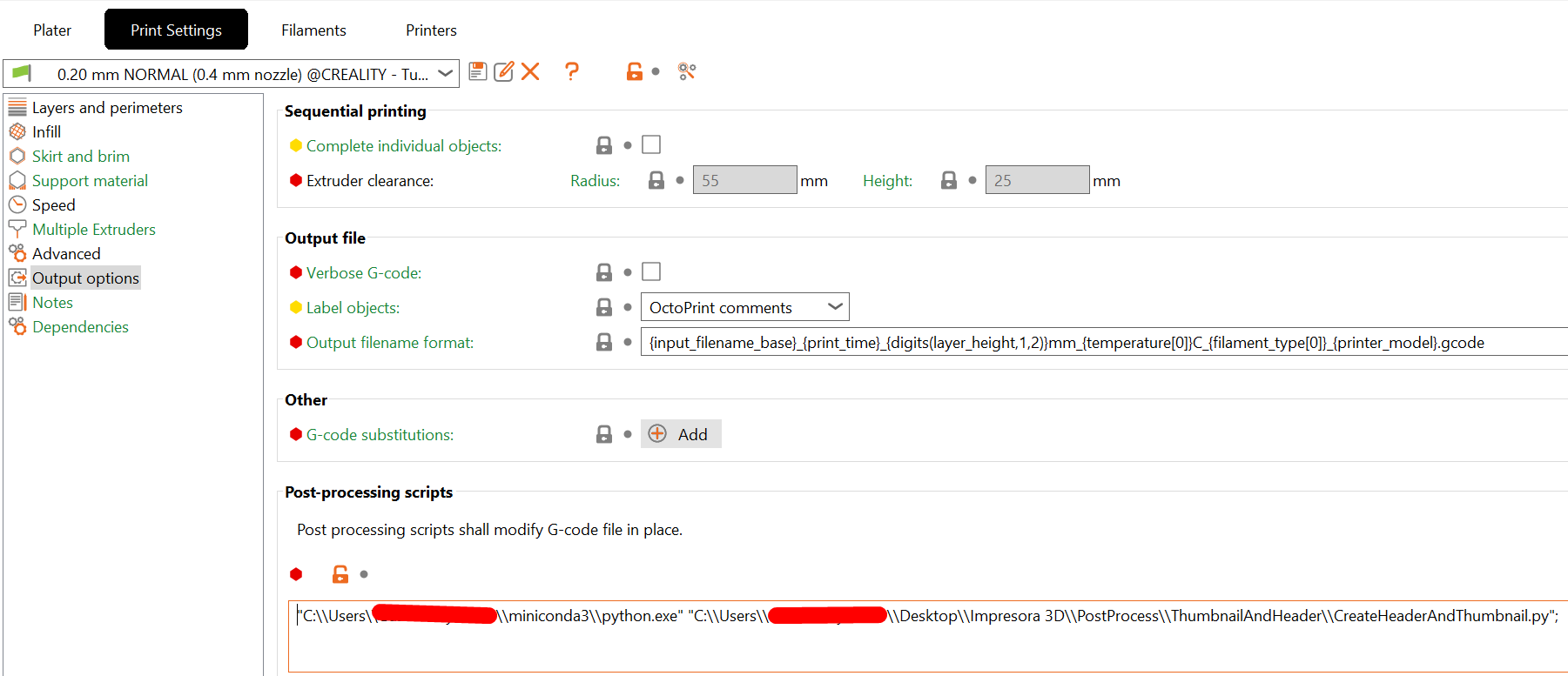
hello try this, its working for my ender 3 s1 plus
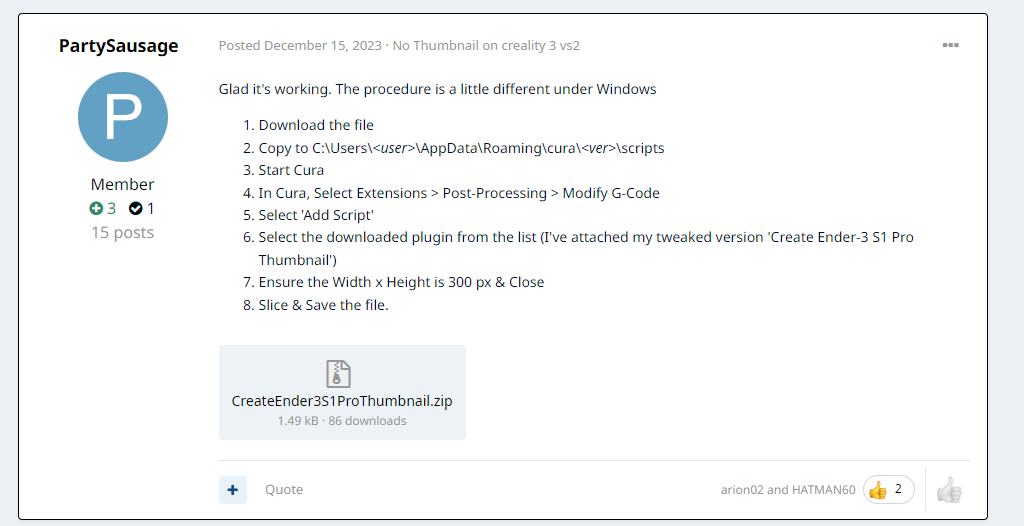
https://community.ultimaker.com/topic/44667-no-thumbnail-on-creality-3-vs2/?_fromLogin=1
hello try this, its working for my ender 3 s1 plus
Hi thanks,
We figured it out, and you can actually find an updated version of the script you linked in post #14
I’m having trouble getting this to show up in Cura 5.5. I copied the text from your post, saved it in Notepad as a .py file in the cura scripts folder and it doesn’t show up.
You can download it here. The instructions for using it are in the forum thread
https://community.ultimaker.com/topic/44667-no-thumbnail-on-creality-3-vs2/#comment-331137
Hi,
works great with cura with the instructions from above…
For Prucaslicer I did copy the code from above to a .py file but get this error while exporting gcode:
Failed starting the script \Users\micha\AppData\Roaming\PrusaSlicer\scripts\thump.py C:\Users\micha\AppData\Local\Temp.608.gcode.pp, Win32 error: 193
Hello! I would like to fix the thumbnail problem on my Ender 3 S1 Plus but I cannot find where to put this code. I am using Prusa Slicer (version 2.8.1). From your instructions it suggests I need to download “Pillow”? I know there is a “G-code thumbnails” setting under the “Printers” → “General” tab, but I have no clue what to set the picture size to. I am very new to messing with Gcode so I am grateful for any help.
You need to write the following under “Print Settings” > “Output options” > “Post-processing scripts”:
"full/filepath/to/python/interpreter" "full/filepath/to/postprocesing/script"
or
"python/interpreter/environment/variable" "full/filepath/to/postprocesing/script"
like so:
This setting is “Print profile” specific, meaning you will have to copy and paste the text in each print profile you use
Ok, a little progress, but I still have issues…
I copied the code from post 16 and pasted into Notepad. I saved as a .py, created a folder and stashed the file in there. I then copied the filepath,
“C:\Users\user\Documents\thumbnailfilefolder\thumbnailGcode.py”,
and pasted it into the “Post-processing scripts” area. In the post above you stated that the “full/filepath/to/python/interpreter” is needed.
Do I need to download a python interpreter?
Also, when I attempted to export the file, I received a message similar to @Hromi:
PrusaSlicer has encountered an error
Failed starting the script C:\Users\user\Documents\thumbnailfilefolder\thumbnailGcode.py C:\Users\user\AppData\Local\Temp.15432.gcode.pp, Win32 error: 193
Thanks for the help.
You need a python interpreter to run the script
The error you are getting is because prusaslicer is trying to execute the python script without an interpreter
Hi,
I haven’t read everything above so I’m not really In this topic…but maybe you’ll find something in the following YouTube explanation.
https://www.youtube.com/watch?v=85ybXf42W7M
I have the same printer and with me it worked immediately.
Poniżej poprawiony kod do OrcaSlicer który nie wymaga zmiany w programie rozdzielczości i kompresji obrazu.
#!/usr/bin/env python3
import base64
import binascii
import io
import os
import re
import sys
import traceback
from PIL import Image
THUMBNAIL_PATTERN = re.compile(
r"; thumbnail(?:_JPG)? begin (?P\d+)x*(?: (?P[0-9 ]+))?\n" # header
r"(?P(?:;.*\n)+?)" # base64 body
r"; thumbnail(?:_JPG)? end",
flags=re.IGNORECASE,
)
def encoded_string_to_gcode_comment(encoded_string):
chunks = 76
return '; ’ + '\n; '.join(
encoded_string[i:i + chunks] for i in range(0, len(encoded_string), chunks)
) + ‘\n’
def parse_thumbnail_blocks(content):
blocks =
for match in THUMBNAIL_PATTERN.finditer(content):
body = match.group(‘body’)
encoded = ‘’.join(line.lstrip('; ').rstrip() for line in body.splitlines())
if not encoded:
continue
try:
decoded = base64.b64decode(encoded)
except (binascii.Error, ValueError):
continue
try:
with Image.open(io.BytesIO(decoded)) as img_png:
img_png_rgb = img_png.convert('RGB')
except Exception:
continue
img_byte_arr = io.BytesIO()
img_png_rgb.save(img_byte_arr, format='jpeg', quality=40, optimize=True)
jpeg_bytes = img_byte_arr.getvalue()
encoded_jpeg = base64.b64encode(jpeg_bytes).decode('ascii')
comment_block = encoded_string_to_gcode_comment(encoded_jpeg)
width = int(match.group('width'))
height = int(match.group('height'))
area = width * height
x1 = int(width / 80) + 1
x2 = width - x1
blocks.append({
'raw': match.group(0),
'width': width,
'height': height,
'area': area,
'jpeg_bytes': jpeg_bytes,
'comment': comment_block,
'header': f"; thumbnail_jpg begin {width}*{height} {len(jpeg_bytes)} {x1} {x2} 500\n",
})
return blocks
def main():
if len(sys.argv) < 2:
print(‘Missing source file argument’)
sys.exit(1)
source_file = sys.argv[1]
with open(source_file, 'r', encoding='utf-8') as src:
content = src.read()
blocks = parse_thumbnail_blocks(content)
if not blocks:
print('No compatible thumbnail block found; leaving file untouched.')
sys.exit(0)
for block in blocks:
content = content.replace(block['raw'], '')
content = re.sub(r'; THUMBNAIL_BLOCK_(?:START|END)\n', '', content, flags=re.IGNORECASE)
selected = max(blocks, key=lambda b: b['area'])
header = selected['header']
encodedjpg_gcode = selected['comment']
tail = '; thumbnail_jpg end\n'
ph = re.search(r'; generated by (.*)\n', content)
if ph is not None:
content = content.replace(ph.group(0), '')
time = 0
match = re.search(r'; estimated printing time \(normal mode\) = (.*)\n', content)
if match is not None:
h = re.search(r'(\d+)h', match.group(1))
hours = int(h.group(1)) if h is not None else 0
m = re.search(r'(\d+)m', match.group(1))
minutes = int(m.group(1)) if m is not None else 0
s = re.search(r'(\d+)s', match.group(1))
seconds = int(s.group(1)) if s is not None else 0
time = hours * 3600 + minutes * 60 + seconds
match = re.search(r'; filament used \[mm\] = ([0-9.]+)', content)
filament = float(match.group(1)) / 1000 if match is not None else 0
match = os.getenv('SLIC3R_LAYER_HEIGHT')
layer = float(match) if match is not None else 0
minx = 0
miny = 0
minz = layer
maxx = 0
maxy = 0
maxz = (content.count('Z.2') + 1) * layer
try:
with open(source_file, 'w', encoding='utf-8') as dest:
dest.write(header)
dest.write(encodedjpg_gcode)
dest.write(tail)
dest.write(';' + '\n')
dest.write('\n')
dest.write(';FLAVOR:Marlin\n')
dest.write(';TIME:{:d}\n'.format(time))
dest.write(';Filament used: {:.6f}\n'.format(filament))
dest.write(';Layer height: {:.2f}\n'.format(layer))
dest.write(';MINX:{:.3f}\n'.format(minx))
dest.write(';MINY:{:.3f}\n'.format(miny))
dest.write(';MINZ:{:.3f}\n'.format(minz))
dest.write(';MAXX:{:.3f}\n'.format(maxx))
dest.write(';MAXY:{:.3f}\n'.format(maxy))
dest.write(';MAXZ:{:.3f}\n'.format(maxz))
content = content.replace('\n\n;\n\n\n;\n; \n', '')
dest.write('\n;\n;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;\n')
if ph is not None:
dest.write(ph.group(0))
dest.write(content)
except Exception:
print('Error writing output file')
traceback.print_exc()
input()
sys.exit(1)
if name == ‘main’:
main()